# Overview
This project provides a REST interface to execute queries on the databuffer.
# Requirements
This project requires Java 8 or greater.
# Deployment
This application runs in a [docker container](https://github.psi.ch/docker/query_rest). Use the instructions provided by [ch.psi.daq.install](https://git.psi.ch/sf_daq/ch.psi.daq.install#query_rest) to install the application on a server.
## Application Properties
Following files define and describe application properties:
- [Cassandra](https://github.psi.ch/sf_daq/ch.psi.daq.cassandra/blob/master/src/main/resources/cassandra.properties) specific properties.
- [Query](https://github.psi.ch/sf_daq/ch.psi.daq.query/blob/master/src/main/resources/query.properties) specific properties..
- [Query REST](https://github.psi.ch/sf_daq/ch.psi.daq.queryrest/blob/master/src/main/resources/queryrest.properties) specific properties.
It is possible to overwrite properties by defining new values in `${HOME}/.config/daq/queryrest.properties`
## Maven
Upload jar to the Maven repository (from ch.psi.daq.buildall):
```bash
./gradlew ch.psi.daq.queryrest:uploadArchives
```
## DropIt
Upload jar DropIt (from ch.psi.daq.buildall):
```bash
./gradlew ch.psi.daq.queryrest:dropIt -x test
```
## Local Instance
[DAQLocal](https://github.psi.ch/sf_daq/ch.psi.daq.daqlocal) provides a local instance of the DAQ system for testing purposes (allowing users/developers to verify their code before they come to PSI to do their research and interact with the DAQ cluster).
# REST Interface
The REST interface is accessible through `https://data-api.psi.ch/sf`.
## Query Channel Names
### Request
```
POST https://:/channels
```
#### Data
```json
{
"regex":"TRFCA|TRFCB",
"backends":[
"sf-databuffer"
],
"ordering":"asc",
"reload":true
}
```
##### Explanation
- **regex**: Reqular expression used to filter channel names. In case this value is undefined, no filter will be applied. Filtering is done using JAVA's [Pattern](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html), more precisely [Matcher.find()](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Matcher.html#find--)).
- **backends**: Array of backends to access (values: sf-databuffer|sf-imagebuffer|sf-archiverappliance). In case this value is undefined, all backends will be queried for their channels.
- **ordering**: The ordering of the channel names (values: **none**|asc|desc).
- **reload**: Forces the server to reload cached channel names (values: **false**|true).
### Example
#### Command
```bash
curl -L -H "Content-Type: application/json" -X POST -d '{"regex": "AMPLT|PHASE"}' https://data-api.psi.ch/sf/channels | python -m json.tool
```
#### Response
```json
[
{
"backend":"sf-databuffer",
"channels":[
"Channel_01_AMPLT",
"Channel_02_AMPLT",
"Channel_03_PHASE"
]
},
{
"backend":"sf-archiverappliance",
"channels":[
"Channel_01_AMPLT",
"Channel_04_PHASE",
"Channel_05_AMPLT"
]
}
]
```
## Channel Configurations
It is possible to query channel configurations like type etc..
The following configuration queries provide the latest known configuration of the channels (see [here](Readme.md#channel_configuration_history) on how to query the channel configuration history).
### Query Channel Configurations
### Request
```
POST https://:/channels/config
```
#### Data
```json
{
"regex":"^SINEG.*PHASE$",
"backends":[
"sf-databuffer"
],
"ordering":"none",
"sourceRegex":"LLRF"
}
```
##### Explanation
- **regex**: Reqular expression used to filter channel names. In case this value is undefined, no filter will be applied. Filtering is done using JAVA's [Pattern](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html), more precisely [Matcher.find()](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Matcher.html#find--)).
- **backends**: Array of backends to access (values: sf-databuffer|sf-imagebuffer|sf-archiverappliance). In case this value is undefined, all backends will be queried for their channels.
- **ordering**: The ordering of the channel names (values: **none**|asc|desc).
- **sourceRegex**: Reqular expression used to filter source names (like e.g. tcp://SINEG01-CVME-LLRF1:20000). In case this value is undefined, no filter will be applied. Filtering is done using JAVA's [Pattern](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html), more precisely [Matcher.find()](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Matcher.html#find--)).
### Example
#### Command
```bash
curl -L -H "Content-Type: application/json" -X POST -d '{"regex": "AMPLT|PHASE|CAM"}' https://data-api.psi.ch/sf/channels/config | python -m json.tool
```
#### Response
```json
[
{
"backend":"sf-databuffer",
"channels":[
{
"name":"Channel_01_AMPLT",
"type":"UInt16",
"shape":[2048],
"modulo":1,
"offset":0,
"backend":"sf-databuffer",
"source":"tcp://SINEG01-CVME-LLRF1:20000"
},
{
"name":"Channel_01_PHASE_AVG",
"type":"Float64",
"shape":[1],
"modulo":1,
"offset":0,
"backend":"sf-databuffer",
"source":"tcp://SINEG01-CVME-LLRF1:20000"
}
]
},
{
"backend":"sf-imagebuffer",
"channels":[
{
"name":"Helges_CAM",
"type":"UInt16",
"shape":[1024,2048],
"modulo":1,
"offset":0,
"backend":"sf-imagebuffer",
"source":"tcp://HELGE_COMPI:9999"
}
]
}
]
```
### Query Specific Channel Configuration
### Request
```
POST https://:/channel/config
```
or
```
GET https://:/channel/config/{channel}
```
#### Data
```json
{
"name":"SINEG01-RCIR-PUP10:SIG-AMPLT",
"backend":"sf-databuffer"
}
```
##### Explanation
- **name**: The channel name (see [here](https://github.psi.ch/sf_daq/ch.psi.daq.queryrest#define-channel-names) on how name clashes will be resolved).
- **backend**: The backend of the channel.
### Example
#### Command
```bash
curl -L -H "Content-Type: application/json" -X POST -d '{"name": "SINEG01-RCIR-PUP10:SIG-AMPLT", "backend":"sf-databuffer"}' https://data-api.psi.ch/sf/channel/config | python -m json.tool
```
or
```bash
curl -L -H "Content-Type: application/json" -X GET https://data-api.psi.ch/sf/channel/config/SINEG01-RCIR-PUP10:SIG-AMPLT | python -m json.tool
```
#### Response
```json
{
"name":"SINEG01-RCIR-PUP10:SIG-AMPLT",
"type":"UInt16",
"shape":[2048],
"modulo":1,
"offset":0,
"backend":"sf-databuffer",
"source":"tcp://SINEG01-CVME-LLRF1:20000"
}
```
## Query Data
### Request
```
POST https://:/query
```
#### Request body
A request is performed by sending a valid JSON object in the HTTP request body. The JSON query defines the channels to be queried, the range, and how the data should be aggregated (this is optional but highly recommended).
#### Data
```json
{
"channels":[
"Channel_01"
],
"range":{
"startPulseId":0,
"endPulseId":3
},
"ordering":"asc",
"configFields":[
"globalDate",
"type"
],
"eventFields":[
"pulseId",
"globalDate",
"value"
],
"aggregation":{
"aggregationType":"value",
"aggregations":[
"min",
"mean",
"max"
],
"nrOfBins":2
},
"response":{
"format":"json",
"compression":"none",
"allowRedirect":true
},
"mapping":{
"incomplete":"provide-as-is"
},
"valueTransformations":[
{
"pattern":"ImageChannel",
"backend":"sf-imagebuffer",
"sequence":[
...
]
},
{
"pattern":"WaveformChannel",
"backend":"sf-databuffer",
"sequence":[
...
]
}
]
}
```
##### Explanation
- **channels**: Array of channels to be queried (see [here](Readme.md#query_channel_names) and [here](Readme.md#define_channel_names)).
- **range**: The range of the query (see [here](Readme.md#query_range)).
- **limit**: An optional limit for the number of elements to retrieve. Limit together with aggregation does not make sense and thus is not supported.
- **ordering**: The ordering of the data (see [here](Readme.md#data_ordering)).
- **configFields**: Array of requested config fields (see [here](Readme.md#requested_fields)). Omitting this field disables the config query.
- **eventFields**: Array of requested event fields (see [here](Readme.md#requested_fields)). Omitting this field results in a default set of event fields.
- **aggregation**: Setting this attribute activates data aggregation (see [here](Readme.md#data_aggregation) for its specification).
- **response**: Specifies the format of the response of the requested data (see [here](Readme.md#response_format)). If this value is not set it defaults to JSON.
- **mapping**: Activates a table like alignment of the response which allows a mapping of values belonging to the same pulse-id/global time (see [here](Readme.md#value_mapping) - usually left undefined).
- **valueTransformations**: Provides the option to apply transformations to channel values (see [here](Readme.md#value_transformations)).
### Define Channel Names
The simplest way to define channels is to use an array of channel name Strings.
```json
"channels":[
"Channel_02",
"Channel_04"
]
```
The query interface will automatically select the backend which contains the channel (e.g., *sf-databuffer* for *Channel_02* and *sf-archiverappliance* for *Channel_04*). In case name clashes exist, the query interface will use following order of priority: *sf-databuffer*, *sf-imagebuffer*, and then *sf-archiverappliance*.
It is also possible to explicitly define the backend to overcome name clashes.
```json
"channels":[
{
"name":"Channel_01",
"backend":"sf-archiverappliance"
},
{
"name":"Channel_01",
"backend":"sf-databuffer"
}
]
```
### Define Query Range
Queries are applied to a range. The following types of ranges are supported.
#### By Pulse-Id
```json
"range":{
"startPulseId":0,
"startInclusive":true,
"startExpansion":false,
"endPulseId":100,
"endInclusive":true,
"endExpansion":false
}
```
- **startPulseId**: The start pulse-id of the range request.
- **startInclusive**: Defines if the start should be considered inclusive (values: **true**|false).
- **startExpansion**: Expands the query start until the first entry before the defined start (values: true|**false**). Binning aggregations are expanded until the start of the bin of that entry.
- **endPulseId**: The end pulse-id of the range request.
- **endInclusive**: Defines if the end should be considered inclusive (values: **true**|false).
- **endExpansion**: Expands the query end until the first entry after the defined end (values: true|**false**). Binning aggregations are expanded until the end of the bin of that entry.
#### By Date
```json
"range":{
"startDate":"2015-08-06T18:00:00.000",
"startInclusive":true,
"startExpansion":false,
"endDate":"2015-08-06T18:59:59.999",
"endInclusive":true,
"endExpansion":false
}
```
- **startDate**: The start date of the time range in the ISO8601 format (such as 1997-07-16T19:20:30.123+02:00 or 1997-07-16T19:20:30.123456789+02:00 (omitting +02:00 falls back to the server's time zone)).
- **startInclusive**: Defines if the start should be considered inclusive (values: **true**|false).
- **startExpansion**: Expands the query start until the first entry before the defined start (values: true|**false**). Binning aggregations are expanded until the start of the bin of that entry.
- **endDate**: The end date of the time range.
- **endInclusive**: Defines if the end should be considered inclusive (values: **true**|false).
- **endExpansion**: Expands the query end until the first entry after the defined end (values: true|**false**). Binning aggregations are expanded until the end of the bin of that entry.
#### By Time
```json
"range":{
"startSeconds":"0.0",
"startInclusive":true,
"startExpansion":false,
"endSeconds":"1.000999999",
"endInclusive":true,
"endExpansion":false
}
```
- **startSeconds**: The start time of the range in seconds since midnight, January 1, 1970 UTC (the UNIX epoch) as a decimal value including fractional seconds.
- **startInclusive**: Defines if the start should be considered inclusive (values: **true**|false).
- **startExpansion**: Expands the query start until the first entry before the defined start (values: true|**false**). Binning aggregations are expanded until the start of the bin of that entry.
- **endSeconds**: The end time of the range in seconds.
- **endInclusive**: Defines if the end should be considered inclusive (values: **true**|false).
- **endExpansion**: Expands the query end until the first entry after the defined end (values: true|**false**). Binning aggregations are expanded until the end of the bin of that entry.
### Data Ordering
```json
"ordering":"asc"
```
- **ordering**: Defines the ordering of the requested data (values: **asc**|desc|none). Use *none* in case ordering does not matter (allows for server side optimizations).
### Requested Fields
```json
"configFields":[
"pulseId",
"globalDate",
"type"
],
"eventFields":[
"pulseId",
"globalDate",
"value"
]
```
- **configFields**: Array of requested config fields (see [here](https://github.psi.ch/sf_daq/ch.psi.daq.domain/blob/master/src/main/java/ch/psi/daq/domain/query/operation/ConfigField.java)) for possible values of config queries.
- **eventFields**: Array of requested event fields (see [here](https://github.psi.ch/sf_daq/ch.psi.daq.domain/blob/master/src/main/java/ch/psi/daq/domain/query/operation/EventField.java) for possible values of data queries.
It is possible to request the time in seconds (since midnight, January 1, 1970 UTC (the UNIX epoch) as a decimal value including fractional seconds - using fields *globalSeconds* and *iocSeconds*), in milliseconds (since midnight, January 1, 1970 UTC (the JAVA epoch) - using fields *globalMillis* and *iocMillis*) or as a ISO8601 formatted String - using fields *globalDate* and *iocDate* (such as 1997-07-16T19:20:30.123456789+02:00).
### Data Aggregation
It is possible (and recommended) to aggregate queried data.
```json
"aggregation":{
"aggregationType":"value",
"aggregations":[
"min",
"mean",
"max"
],
"nrOfBins":2
}
```
- **aggregationType**: Specifies the type of aggregation (see [here](https://github.psi.ch/sf_daq/ch.psi.daq.domain/blob/master/src/main/java/ch/psi/daq/domain/query/operation/AggregationType.java)). The default type is *value* aggregation (e.g., sum([1,2,3])=6). Alternatively, it is possible to define *index* aggregation for multiple arrays in combination with binning (e.g., sum([1,2,3], [3,2,1]) = [4,4,4]).
- **aggregations**: Array of requested aggregations (see [here](https://github.psi.ch/sf_daq/ch.psi.daq.domain/blob/master/src/main/java/ch/psi/daq/domain/query/operation/Aggregation.java) for possible values). These values will be added to the *data* array response.
- **extrema**: Array of requested extrema (see [here](https://github.psi.ch/sf_daq/ch.psi.daq.domain/blob/master/src/main/java/ch/psi/daq/domain/query/operation/Extrema.java) for possible values). These values will be added to the *data* array response.
- **nrOfBins**: Activates data binning. Specifies the number of bins the pulse/time range should be divided into (e.g., `"nrOfBins":2`).
- **durationPerBin**: Activates data binning. Specifies the duration per bin for time-range queries (using duration makes this binning strategy consistent between channel with different update frequencies). The duration is defined as a [ISO-8601](https://en.wikipedia.org/wiki/ISO_8601#Durations) duration (e.g., `"durationPerBin":"PT1H"` for 1 hour, `"durationPerBin":"PT2S"` for 2 seconds, `"durationPerBin":"PT0.05S"` for 50 milliseconds etc.). The resolution is in milliseconds and thus the minimal duration is 1 millisecond.
- **pulsesPerBin**: Activates data binning. Specifies the number of pulses per bin for pulse-range queries (e.g., `"pulsesPerBin":100` - using number of pulses makes this binning strategy consistent between channel with different update frequencies).
### Response Format
It is possible to specify the response format the queried data should have.
```json
"response":{
"format":"json",
"compression":"none",
"allowRedirect":true
}
```
- **format**: The format of the response (values: **json**|csv). Please note that `csv` does not support `index` and `extrema` aggregations.
- **compression**: Responses can be compressed when transferred from the server (values: **none**|gzip). If compression is enabled, you have to tell `curl` that the data is compressed by defining the attribute `--compressed` so that it decompresses the data automatically.
- **allowRedirect**: Defines it the central query rest server is allowed to redirect queries to the query rest server of the actual backend given that the query allows for it (values: **true**|false). Redirect needs to be enabled in `curl` using the `-L` option.
### Value Mapping
It is possible to map values based on their pulse-id/global time. Setting this option activates a table like alignment of the response which differs from the standard response format.
```json
"mapping":{
"incomplete":"provide-as-is",
"alignment":"by-pulse",
"aggregations":["count","min","mean","max"]
}
```
- **incomplete**: Defines how incomplete mappings should be handled (e.g., when the values of two channels should be mapped but these channels have different frequencies or one was not available at the specified query range (values: **provide-as-is**|drop|fill-null). *provide-as-is* provides the data as recorded, *drop* discards incomplete mappings, and *fill-null* fills incomplete mappings with a *null* string (simplifies parsing).
- **alignment**: Defines how the events should be aligned to each other (values: **by-pulse**|by-time|none). In case alignment is undefined it will be selected based on the query type (query by pulse-id or by time). _none_ will simply add one event of a channel after the other (independent of other channels).
- **aggregations**: In case several events are mapped into the same bin (e.g. due to activated binning or duplicated pulse-ids) the values will be aggregated based on this parameter (in case it is undefined it will use the global/default aggregations).
### Value Transformations
It is possible to apply transformations to values. These transformations are available as *transformedValue* in the response (the format/value of *transformedValue* can differ based on the transformation sequence).
```json
"valueTransformations":[
{
"pattern":"ChannelNamePattern",
"backend":"sf-databuffer",
"sequence":[
...
]
}
]
```
- **valueTransformations**: An array of different value transformations. Assigning transformations to queried channels is done using regular expressions applied to channel names (see: [Pattern](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html), more precisely using [Matcher.find()](https://docs.oracle.com/javase/8/docs/api/java/util/regex/Matcher.html#find--)) whereas a longer match sequence is considered superior to a shorter match sequence.
- **pattern**: The regular expression applied to channel names (e.g., "" applies to all channel, '\^SINEG01' to all channels starting with SINEG01 like '**SINEG01**-RCIR-PUP10:SIG-AMPLT').
- **backend**: The backend (usually left undefined).
- **sequence**: A sequence of transformation operations (see [Value Transformation Operations](Readme.md#value_transformation_operations) for examples).
### Value Transformation Operations
#### Image Resize
The following transformation sequence resizes images by the factor of 8, sets the value range to [400...4000], uses the *temperature* color model, and provides the image as a base64 encoded string.
```json
"valueTransformations":[
{
"pattern":"Image",
"backend":"sf-imagebuffer",
"sequence":[
{
"imageResize":{
"downScaleFactor":8,
"valueAggregation":"first-value"
},
"valueFunctions":[
{
"min":400.0,
"mapTo":400.0
},
{
"max":4000.0,
"mapTo":4000.0
}
],
"colorModel":{
"modelType":"temperature",
"nrOfColors":32,
"colors":[
"#3B4CC0",
"#B40426"
]
}
},
{
"imageFormat":"png",
"imageEncoder":"base64string"
}
]
}
]
```
- **imageResize**: The image resize operation.
- **downScaleFactor**: The image downscale factor (e.g. a factor of 8 reduces a area of 8x8 pixels into one pixel).
- **valueAggregation**: Defines how the pixel values should be aggregated (values: **first-value**|max-value|mean-value). *first-value* uses the first value of the reduction area (very fast but signals might get lost), *max-value* uses the max value of the reduction area, and *mean-value* the mean value of the reduction area.
- **valueFunctions**: Array of functions to be applied to pixel values.
- **min**: Map all values smaller than the defined values to the *mapTo* value. Allows to define a filter to eliminate noise (using "mapTo":0) or to set a lower value bound (e.g. to focus on a specific pixel value range - need to be used together with the *max* value function). In case *mapTo* is not defined it defaults to *min*.
- **max**: Map all values bigger than the defined values to the *mapTo* value. Can be used to set a upper value bound (e.g. to focus on a specific pixel value range - need to be used together with the *min* value function). In case *mapTo* is not defined it defaults to *max*.
- **colorModel**: The color model to be used for the image.
- **modelType**: The color model type (values: linear|**temperature**|gradient). Each type has a decent default color scheme (see [linear](doc/images/colormodel/Linear_256.jpg), [temperature](doc/images/colormodel/Temperature_256.jpg), and [gradient](doc/images/colormodel/Rainbow_256.jpg) for examples).
- **nrOfColors**: The number of colors to map between the min. and max. pixel value (use a power of 2 like 16, 32, 64, 128, or 256). The more colors used the more details will be visible but the larger the images will get).
- **colors**: The colors to use for the color model. *linear* uses grayscale, *temperature* blue to red, and *gradient* a rainbow (blue, cyan, green, yellow, red) color scheme as default (leave this option undefined to use defaults - see [linear](doc/images/colormodel/Linear_256.jpg), [temperature](doc/images/colormodel/Temperature_256.jpg), and [gradient](doc/images/colormodel/Rainbow_256.jpg) for examples).
- **imageFormat**: The output image format (values: **png**|jpg).
- **imageEncoder**: The encoding of the image (values: **base64string**|byte).
Applying an image resize transformation has the advantage that the computation is done on the backend resulting in much less data transfer.
#### Value Sampling
The following transformation sequence resizes images by the factor of 4, filters all values below 200 (considers values below 200 as noise), and provides the image in the raw format.
This transformation could potentially also be used for other value forms than images.
```json
"valueTransformations":[
{
"pattern":"Image",
"backend":"sf-imagebuffer",
"sequence":[
"valueSampler":{
"downSampleFactor":4,
"valueAggregation":"first-value"
},
"valueFunctions":[
{
"min":200.0,
"mapTo":0.0
}
]
]
}
]
```
- **valueSampler**: The value sampling operation.
- **downSampleFactor**: The downsample factor (e.g. a factor of 4 reduces a square of 4x4 pixels into one pixel or 4 elements of a waveform into on element).
- **valueAggregation**: Defines how the values should be aggregated (values: **first-value**|max-value|mean-value). *first-value* uses the first value of the reduction area (very fast but signals might get lost), *max-value* uses the max value of the reduction area, and *mean-value* the mean value of the reduction area.
- **valueFunctions**: Array of functions to be applied to values.
- **min**: Map all values smaller than the defined values to the *mapTo* value. Allows to define a filter to eliminate noise (using "mapTo":0) or to set a lower value bound. In case *mapTo* is not defined it defaults to *min*.
- **max**: Map all values bigger than the defined values to the *mapTo* value. Can be used to set a upper value bound. In case *mapTo* is not defined it defaults to *max*.
Applying a value sampling transformation has the advantage that the computation is done on the backend resulting in much less data transfer.
The response has the format '"transformedValue":{"shape":[width,height],"value":[value1,value2,...]}'.
### Example Queries
The following examples build on waveform data (see below). They also work for scalars (consider it as a waveform of length = 1) and images (waveform of length = dimX * dimY).
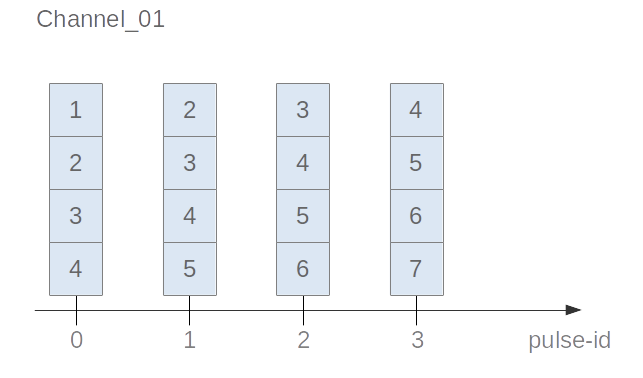
```json
[
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_01"
},
"data":[
{
"iocSeconds":"0.000000000",
"pulseId":0,
"globalSeconds":"0.000000000",
"shape":[
4
],
"value":[1,2,3,4]
},
{
"iocSeconds":"0.010000000",
"pulseId":1,
"globalSeconds":"0.010000000",
"shape":[
4
],
"value":[2,3,4,5]
},
{
"iocSeconds":"0.020000000",
"pulseId":2,
"globalSeconds":"0.020000000",
"shape":[
4
],
"value":[3,4,5,6]
},
{
"iocSeconds":"0.030000000",
"pulseId":3,
"globalSeconds":"0.030000000",
"shape":[
4
],
"value":[4,5,6,7]
}
]
},
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_02"
},
"data":[
{
"iocSeconds":"0.000000000",
"pulseId":0,
"globalSeconds":"0.000000000",
"shape":[
4
],
"value":[1,2,3,4]
},
{
"iocSeconds":"0.010000000",
"pulseId":1,
"globalSeconds":"0.010000000",
"shape":[
4
],
"value":[2,3,4,5]
},
{
"iocSeconds":"0.020000000",
"pulseId":2,
"globalSeconds":"0.020000000",
"shape":[
4
],
"value":[3,4,5,6]
},
{
"iocSeconds":"0.030000000",
"pulseId":3,
"globalSeconds":"0.030000000",
"shape":[
4
],
"value":[4,5,6,7]
}
]
}
]
```
### Query Examples
#### Query by Pulse-Id Range
```json
{
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01"
]
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
See JSON representation of the data above.
#### Query by Time Range
```json
{
"range":{
"startSeconds":"0.0",
"endSeconds":"0.030999999"
},
"channels":[
"Channel_01"
]
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"range":{"startSeconds":"0.0","endSeconds":"0.030999999"},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
See JSON representation of the data above.
#### Query by Date Range
```json
{
"range":{
"startDate":"1970-01-01T01:00:00.000",
"endDate":"1970-01-01T01:00:00.030"
},
"channels":[
"Channel_01"
]
}
```
The supported date format is ISO8601 (such as 1997-07-16T19:20:30.123+02:00 or 1997-07-16T19:20:30.123456789+02:00 (omitting +02:00 falls back to the server's time zone)).
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"range":{"startDate":"1970-01-01T01:00:00.000","endDate":"1970-01-01T01:00:00.030"},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
See JSON representation of the data above.
#### Querying Archiver Appliance
```json
{
"range":{
"startSeconds":"0.0",
"endSeconds":"0.030999999"
},
"channels":[
{
"name": "Channel_01",
"backend":"sf-archiverappliance"
},
{
"name": "Channel_02",
"backend":"sf-archiverappliance"
}
]
}
```
Archiver Appliance supports queries by *time range* and *date range* only (as it has no notion about pulse-id).
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"range":{"startSeconds":"0.0","endSeconds":"0.030999999"},"channels":[{"name": "Channel_01","backend":"sf-archiverappliance"}]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
See JSON representation of the data above.
#### Query Using Compression
```json
{
"response":{
"compression":"gzip"
},
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01"
]
}
```
##### Command (gzip)
The `curl` command has a `--compressed` option to decompress data automatically.
```bash
curl --compressed -H "Content-Type: application/json" -X POST -d '{"response":{"compression":"gzip"},"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
#### Querying for Specific Fields
Allows for server side optimizations since not all data needs to be retrieved.
```json
{
"eventFields":["pulseId","value"],
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01"
]
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"eventFields":["pulseId","value"],"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
```json
[
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_01"
},
"data":[
{
"pulseId":0,
"value":[1,2,3,4]
},
{
"pulseId":1,
"value":[2,3,4,5]
},
{
"pulseId":2,
"value":[3,4,5,6]
},
{
"pulseId":3,
"value":[4,5,6,7]
}
]
}
]
```
#### Query CSV Format
```json
{
"response":{
"format":"csv"
},
"range":{
"startPulseId":0,
"endPulseId":4
},
"channels":[
"channel1",
"channel2"
],
"eventFields":[
"channel",
"pulseId",
"iocSeconds",
"globalSeconds",
"shape",
"eventCount",
"value"
]
}
```
##### Command
```bash
curl -L -H "Content-Type: application/json" -X POST -d '{"response":{"format":"csv"},"range":{"startPulseId":0,"endPulseId":4},"channels":["channel1","channel2"],"eventFields":["channel","pulseId","iocSeconds","globalSeconds","shape","eventCount","value"]}' https://data-api.psi.ch/sf/query
```
##### Response
The response is in CSV.
```text
channel;pulseId;iocSeconds;globalSeconds;shape;eventCount;value
testChannel1;0;0.000000000;0.000000000;[1];1;0
testChannel1;1;0.010000000;0.010000000;[1];1;1
testChannel1;2;0.020000000;0.020000000;[1];1;2
testChannel1;3;0.030000000;0.030000000;[1];1;3
testChannel1;4;0.040000000;0.040000000;[1];1;4
testChannel2;0;0.000000000;0.000000000;[1];1;0
testChannel2;1;0.010000000;0.010000000;[1];1;1
testChannel2;2;0.020000000;0.020000000;[1];1;2
testChannel2;3;0.030000000;0.030000000;[1];1;3
testChannel2;4;0.040000000;0.040000000;[1];1;4
```
#### Data Ordering
```json
{
"ordering":"desc",
"eventFields":["pulseId","value"],
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01"
]
}
```
Use **none** in case ordering does not matter (allows for server side optimizations).
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"ordering":"desc","eventFields":["pulseId","value"],"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
```json
[
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_01"
},
"data":[
{
"pulseId":3,
"value":[4,5,6,7]
},
{
"pulseId":2,
"value":[3,4,5,6]
},
{
"pulseId":1,
"value":[2,3,4,5]
},
{
"pulseId":0,
"value":[1,2,3,4]
}
]
}
]
```
#### Query Aggregated Values
```json
{
"aggregation":{
"aggregationType":"value",
"aggregations":["min","mean","max"]
},
"eventFields":["pulseId","value"],
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01"
]
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"aggregation":{"aggregationType":"value","aggregations":["min","mean","max"]},"eventFields":["pulseId","value"],"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
```json
[
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_01"
},
"data":[
{
"pulseId":0,
"value":{
"min":1.0,
"max":4.0,
"mean":2.5
}
},
{
"pulseId":1,
"value":{
"min":2.0,
"max":5.0,
"mean":3.5
}
},
{
"pulseId":2,
"value":{
"min":3.0,
"max":6.0,
"mean":4.5
}
},
{
"pulseId":3,
"value":{
"min":4.0,
"max":7.0,
"mean":5.5
}
}
]
}
]
```
Illustration of array value aggregation:
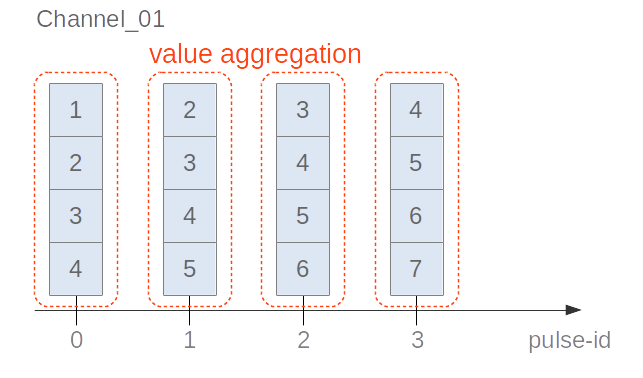
#### Value Aggregation with Binning (nrOfBins)
```json
{
"aggregation":{
"nrOfBins":2,
"aggregationType":"value",
"aggregations":["min","mean","max"]
},
"eventFields":["pulseId","value"],
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01"
]
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"aggregation":{"nrOfBins":2,"aggregationType":"value","aggregations":["min","mean","max"]},"eventFields":["pulseId","value"],"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
```json
[
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_01"
},
"data":[
{
"pulseId":0,
"value":{
"min":1.0,
"max":5.0,
"mean":3.0
}
},
{
"pulseId":2,
"value":{
"min":3.0,
"max":7.0,
"mean":5.0
}
}
]
}
]
```
Illustration of array value aggregation with additional binning:
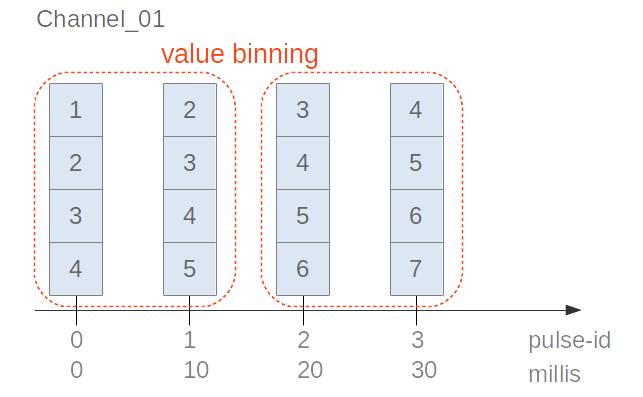
#### Value Aggregation with Binning (durationPerBin/pulsesPerBin)
**durationPerBin** specifies the duration per bin for time-range queries (using duration makes this binning strategy consistent between channel with different update frequencies). The duration is defined as a [ISO-8601](https://en.wikipedia.org/wiki/ISO_8601#Durations) duration (e.g., `PT1H` for 1 hour, `PT2S` for 2 seconds, `PT0.05S` for 50 milliseconds etc.). The resolution is in milliseconds and thus the minimal duration is 1 millisecond.
**pulsesPerBin** specifies the number of pulses per bin for pulse-range queries (using number of pulses makes this binning strategy consistent between channel with different update frequencies).
```json
{
"aggregation":{
"pulsesPerBin":2,
"aggregationType":"value",
"aggregations":["min","mean","max"]
},
"eventFields":["globalMillis","value"],
"range":{
"startSeconds":"0.0",
"endSeconds":"0.030000000"
},
"channels":[
"Channel_01"
]
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"aggregation":{"pulsesPerBin":2,"aggregationType":"value","aggregations":["min","mean","max"]},"eventFields":["globalMillis","value"],"range":{"startSeconds":"0.0","endSeconds":"0.030000000"},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
```json
[
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_01"
},
"data":[
{
"globalMillis":0,
"value":{
"min":1.0,
"max":5.0,
"mean":3.0
}
},
{
"globalMillis":20,
"value":{
"min":3.0,
"max":7.0,
"mean":5.0
}
}
]
}
]
```
Illustration of array value aggregation with additional binning:
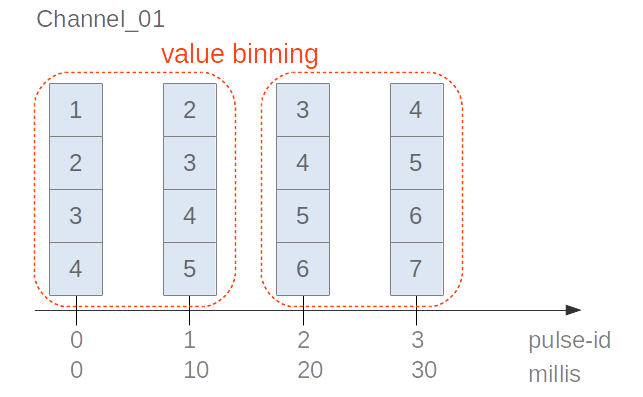
#### Index Aggregation
```json
{
"aggregation":{
"pulsesPerBin":1,
"aggregationType":"index",
"aggregations":["min","mean","max","sum"]
},
"eventFields":["pulseId","value"],
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01"
]
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"aggregation":{"nrOfBins":1,"aggregationType":"index","aggregations":["min","max","mean","sum"]},"eventFields":["pulseId","value"],"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
```json
[
{
"channel":{
"backend": "sf-databuffer",
"name": "Channel_01"
},
"data":[
{
"pulseId":0,
"value":[
{
"min":1.0,
"max":4.0,
"mean":2.5,
"sum":10.0
},
{
"min":2.0,
"max":5.0,
"mean":3.5,
"sum":14.0
},
{
"min":3.0,
"max":6.0,
"mean":4.5,
"sum":18.0
},
{
"min":4.0,
"max":7.0,
"mean":5.5,
"sum":22.0
}
]
}
]
}
]
```
Illustration of array index aggregation with additional with binning (several nrOfBins are also possible):

#### Query with Value Mapping
Maps values based on their pulse-id/global time. Please note that the response format differs in order to represent the value mapping. Lets assume for this query that *Channel_02* only provides events for even pulse-ids.
```json
{
"eventFields":["pulseId","value"],
"range":{
"startPulseId":0,
"endPulseId":3
},
"channels":[
"Channel_01",
"Channel_02"
],
"mapping":{
"incomplete":"provide-as-is"
}
}
```
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"eventFields":["pulseId","value"],"range":{"startPulseId":0,"endPulseId":3},"channels":["Channel_01","Channel_02"],"mapping":{"incomplete":"provide-as-is"}}' https://data-api.psi.ch/sf/query | python -m json.tool
```
##### Response
With *provide-as-is*, the response will contain all available data. In case *drop* would be used, only events with even pulse-ids would be returned (assuming *Channel_02* only provides events for even pulse-ids).
```json
{
"data":[
[
{
"channel":"Channel_01",
"backend":"sf-databuffer",
"pulseId":0,
"value":0
},
{
"channel":"Channel_02",
"backend":"sf-databuffer",
"pulseId":0,
"value":0
}
],
[
{
"channel":"Channel_01",
"backend":"sf-databuffer",
"pulseId":1,
"value":1
}
],
[
{
"channel":"Channel_01",
"backend":"sf-databuffer",
"pulseId":2,
"value":2
},
{
"channel":"Channel_02",
"backend":"sf-databuffer",
"pulseId":2,
"value":2
}
],
[
{
"channel":"Channel_01",
"backend":"sf-databuffer",
"pulseId":3,
"value":3
}
]
]
}
```
### Query Channel Configuration History
### Request
```
POST https://:/query/config
```
#### Request body
A request is performed by sending a valid JSON object in the HTTP request body. The JSON query defines the channels to be queried and the range.
#### Data
```json
{
"channels":[
"Channel_01"
],
"range":{
"startPulseId":0,
"endPulseId":3
},
"ordering":"asc",
"configFields":[
"pulseId",
"globalDate",
"type"
],
"response":{
"format":"json",
"compression":"none",
"allowRedirect":true
}
}
```
##### Explanation
The query format is equivalent to the data query (see [here](Readme.md#query_data) for further explanations - be aware that the url is not equivalent).
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"range":{"startDate":"2017-01-01T01:00:00.000","endDate":"2017-11-01T01:00:00.030"},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query/config | python -m json.tool
```
### Query Pulse-Id Time Mapping
### Request
```
POST https://:/query/mapping
```
#### Request body
A request is performed by sending a valid JSON object in the HTTP request body. The JSON query defines the channels to be queried and the range. In case no channels are defined the global pulseId-time mapping will be queried (otherwise the channel specific mapping - e.g. some events might have been delete).
#### Data
```json
{
"channels":[
"Channel_01"
],
"range":{
"startPulseId":0,
"endPulseId":3
},
"ordering":"asc",
"eventFields":[
"pulseId",
"globalDate"
],
"response":{
"format":"json",
"compression":"none",
"allowRedirect":true
}
}
```
##### Explanation
The query format is equivalent to the data query (see [here](Readme.md#query_data) for further explanations - be aware that the url is not equivalent).
##### Command
```bash
curl -H "Content-Type: application/json" -X POST -d '{"range":{"startDate":"2017-01-01T01:00:00.000","endDate":"2017-11-01T01:00:00.030"},"channels":["Channel_01"]}' https://data-api.psi.ch/sf/query/mapping | python -m json.tool
```
or
```bash
curl -H "Content-Type: application/json" -X POST -d '{"range":{"startPulseId":4,"endPulseId":20},"eventFields":["pulseId","globalSeconds"]}' https://data-api.psi.ch/sf/query/mapping | python -m json.tool
```